 NYC's Blog
NYC's Blog 查询处理器是数据库管理系统中一个部件集合,它允许用户使用SQL语言在较高层次上表达查询,其主要职责是将用户的各种命令转化为数据库上的操作序列并执行。查询处理分为查询编译和查询执行两个阶段。查询编译的主要任务是根据用户的查询语句生成数据库中的最优执行计划,在此过程中要考虑视图、规则及表的连接路径等问题。查询执行主要考虑执行计划时所采用的算法问题。
1. 查询编译器概述
当PostgreSQL的后台服务进程Postgres接收到查询语句后,首先将其传递到查询分析模块,然后进行词法、语法和语义分析。若是简单的命令(例如建表、创建用户、备份等)则将其分配到功能性命令处理模块;对于复杂的命令(SELECT/INSERT/DELETE/UPDATE)则要为其构建查询树(Query结构体),然后交给查询重写模块。查询重写模块接收到查询树后,按照该查询所涉及的规则和视图对查询树进行重写,生成新的查询树。生成路径模块依据重写过的查询树,考虑关系的访问方式、连接方式和连接顺序等问题,采用动态规划算法或遗传算法,生成最优的表连接路径。最后,由最优路径生成可执行的计划,并将其传递到查询执行模块执行。下图分别是查询处理的整个流程以及每个模块的功能:
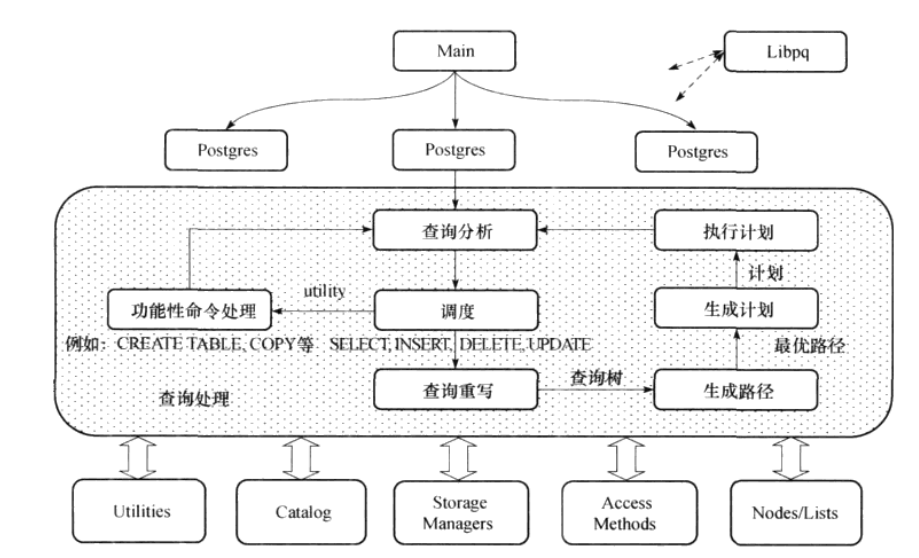
图1. 查询处理的整个流程
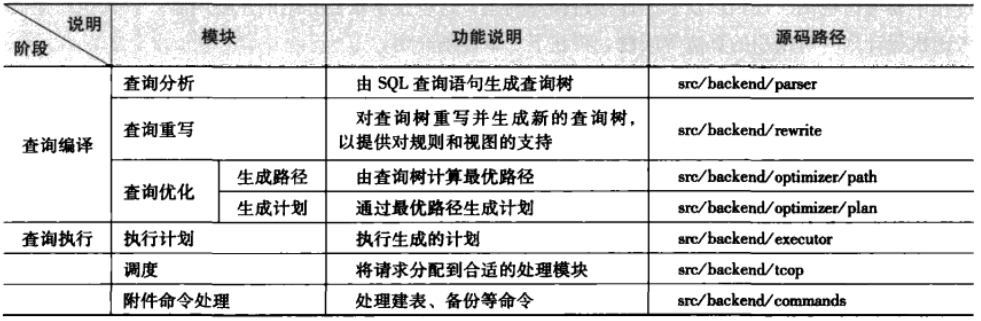
图2. 查询处理各模块说明
对于用户输入SQL命令,统一由exec_simple_query函数处理,该函数将调用pg_parse_query完成词法和语法分析并产生分析树,接下来调用pg_analyze_and_rewrite函数逐个对分析树进行语义分析和重写:在该函数中又会调用parse_analyze函数进行语义分析并创建查询树(Query结构),函数pg_rewrite_query则负责对查询树进行重写。各函数调用关系如下:

图3. 查询处理函数调用
2. 查询执行器概述
查询编译器将用户提交的SQL查询语句转变成执行计划之后,由查询执行器继续执行查询的处理过程。在查询执行阶段,将根据执行计划进行数据提取、处理、存储等一系列活动,以完成整个查询的执行过程。查询执行过程更像一个结构良好的裸机,执行计划为输入,执行相应的功能。执行器的框架结构如下图所示。同查询编译器一样,查询执行器也是被函数exec_simple_query调用,只是调用顺序上查询编译器在前,查询执行器在后。从总体上看,查询执行器实际就是按照执行计划的安排,有机的调用存储、索引、并发等模块,按照各种执行计划中各种计划节点的实现算法来完成数据的读取或者修改的过程。

图4. 查询执行器框架
如图,查询执行器有四个主要的子模块:Portal、ProcessUtility、Executor和特定功能的子模块部分。由于查询执行器将查询分为两大类别,分别由子模块ProcessUtility和Executor负责执行,因此查询执行器会首先在Portal模块根据输入执行计划选择相应的处理模块(Portal模块也称为策略选择模块)。选择执行策略后,会将执行控制流程交给相应的处理部件(即ProcessUtility或Executor),两者的处理方式迥异,执行过程和相关数据结构都有很大的不同。Executor输入包含了一个查询计划树(Plan Tree),用于实现针对于数据表中元组的增删查改等操作。二ProcessUtility处理其他各种情况,这些情况间差别很大(如游标、表的模式创建、事物相关操作等),所以在ProcessUtility中为每种情况实现了处理流程。当然,在两种执行模块中都少不了各种辅助的子系统,例如执行过程中会涉及表达式的计算、投影操作以及元组操作等,这些功能相对独立,并且在整个查询过程中会被反复调用,因此将其单独划分为一个模块(特定功能子模块)。
查询编译器和查询执行器是数据库中比较核心的模块,里面涉及很多算法和知识点,后面慢慢学习,一个点一个点去理解掌握。
本文总结字《PostgreSQL数据库内核分析》一书。
评论已关闭